My friend Willem Vermeulen and I have been playing around with AI the past few weeks to try software for handwritten text recognition. We’ve been using it to transcribe records of Oosterhout in Noord-Brabant, where we both have ancestors.
Short version: it is a game-changer and will forever change how I do genealogy.
Loghi
The software we used is Loghi, Linux-based software developed by the KNAW (royal Dutch academy for sciences) in collaboration with the National Archives. It is available as open source via GitHub.
Warning: this is not a consumer product. It’s a work-in-progress that was released so that other developers could use it. Willem and I are both experienced IT professionals and it took us hours of tweaking to get it running on our specific computers. If you’re confortable in Linux, Python, and Docker, you might want to try it.
Loghi comes with a trained model for Dutch manuscripts in the 1600s and 1700s. This means that the program was giving a training set of scans with correct transcriptions, which it used to learn how to read the old script. At present, no models have been released for other languages or periods. You can train your own model, but I have not tried that yet.
We downloaded images from the Regionaal Archief Tilburg (using a script that ChatGPT helped me write) for different records of Oosterhout, including court records, town records, and notarial records. We then asked Loghi to transcribe them. It does about 200-500 scans per hour, depending on the computer and amount of text on the page. I let my computer do that at night.
Over the past six weeks, we transcribed over 200,000 scans (about 350,000 pages), amounting to almost 50 million words!
The results are astounding. There are errors: recognition errors and line order errors. But even with those, the results are useful for searching.
VerledenTekst
We had the transcriptions in an XML format, and Willem wrote a script to turn those into text-files we could search. But that is not a fun way to share the results, is it?
So Willem, being Willem, built a whole website around it to make the results searchable! We launched the website last Thursday. It’s called VerledenTekst (“Past Text,” a wordplay on “past tense,” that ChatGPT came up with). Microsoft Designer created a logo for us.

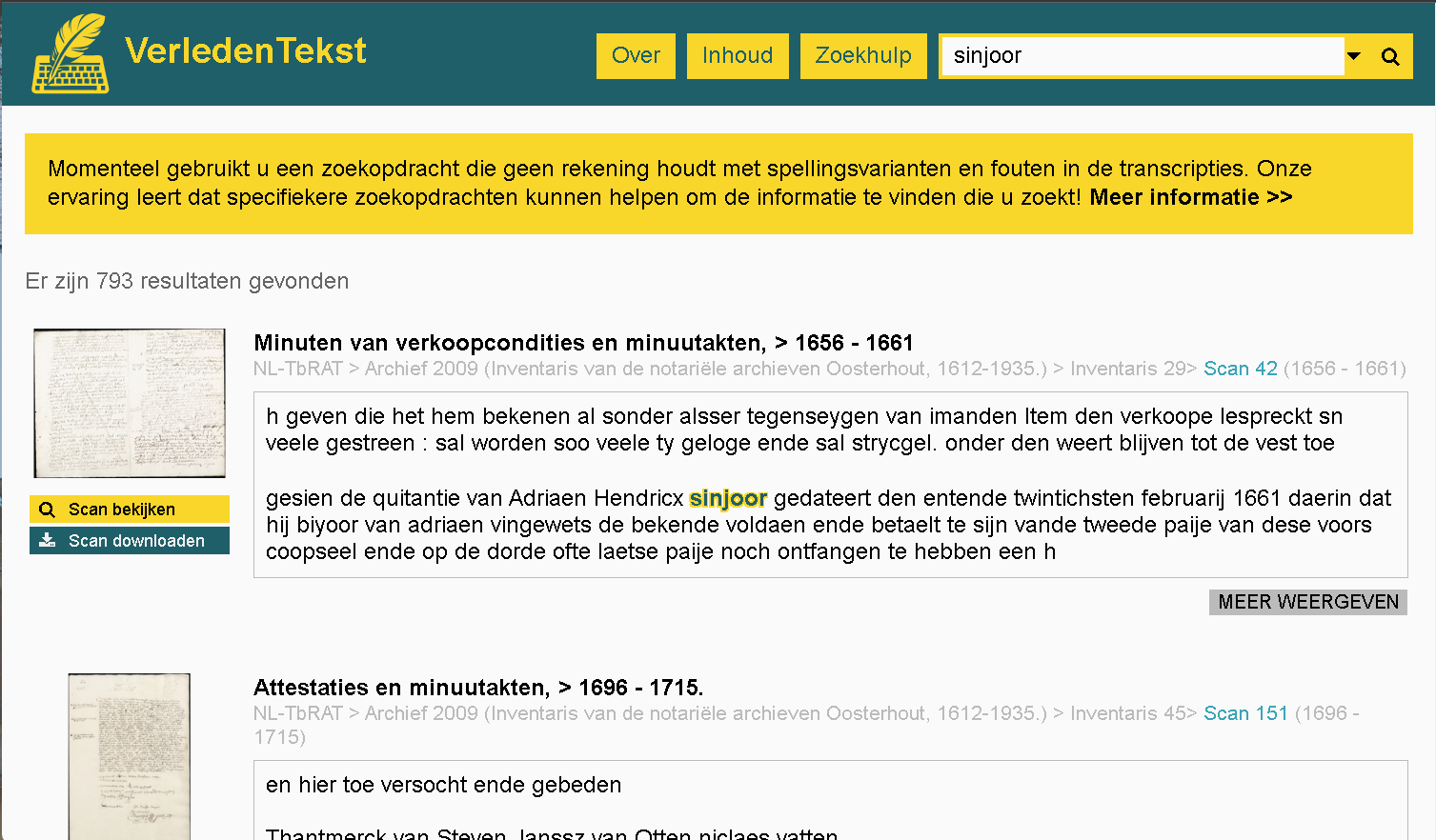
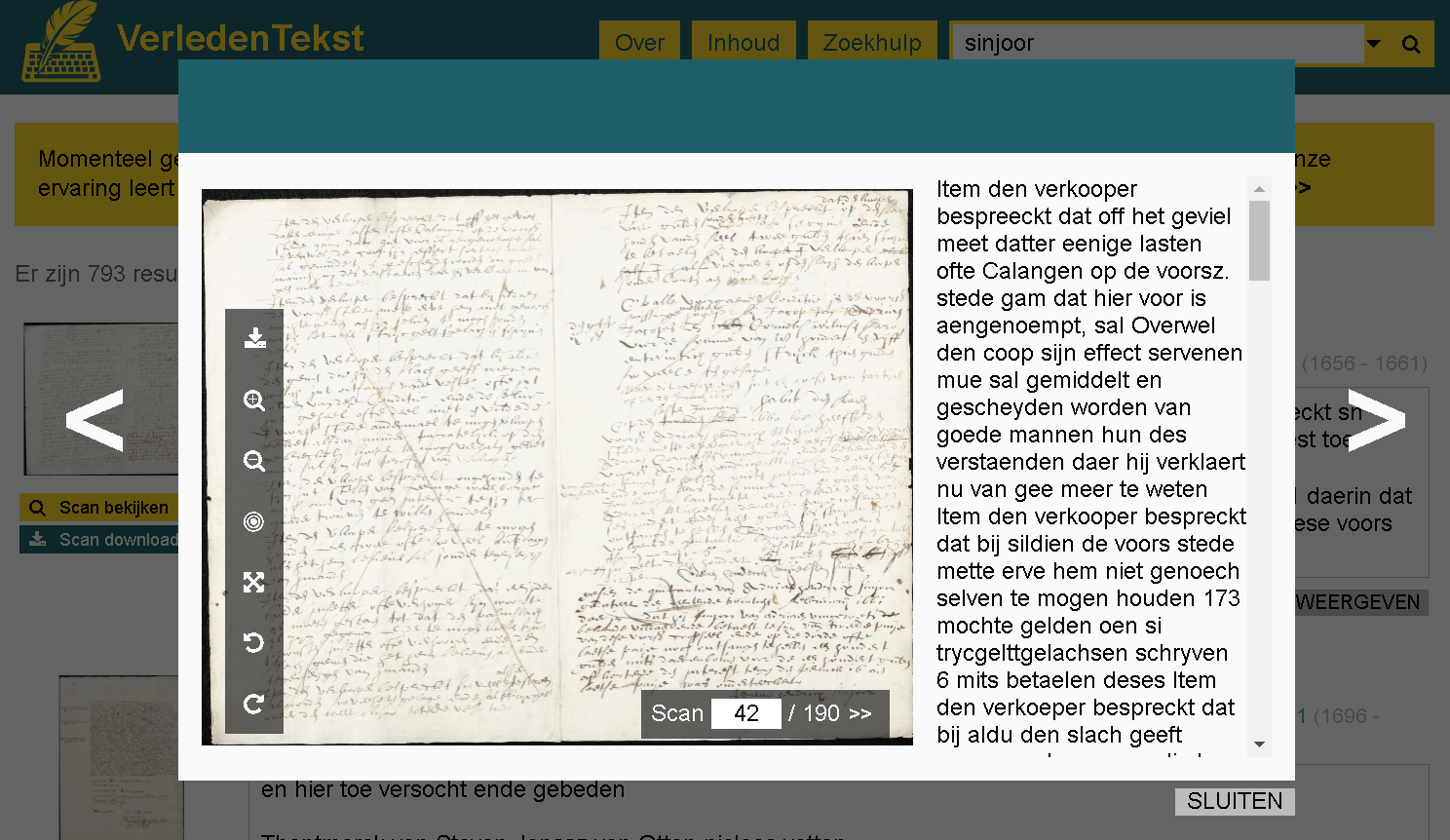
On VerledenTekst, you can search for a term and it will give you a list of scans the term appears in. Results are presented in the order in the archives (by records group > call number > scan number) so related scans are presented near each other. You can click the scan to see the full image next to the transcription, and browse to previous and next pages. You can download the scan.
Some ideas for terms:
- Names of your ancestors, their neighbors or associates
- Field names of land your ancestors owned, to see who owned it before
- Terms of items in inventories such as “chocola” if you are interested in when chocolate was first used in that town.
As you can see, the texts are not just useful for genealogists but for historians too. You can search for variations using regular expressions, see zoekhulp for examples.
The Inhoud [contents] has an overview of all the record groups and call numbers that have been transcribed yet. You can click through to the images and transcriptions.
We have several ideas for improvement, including an English version, but for now we are happy to have a website where others can use the results.
Example results
Here are some discoveries I have made using the website.
My ancestor Adriaen Hendricx Sinjoor signed a quitclaim in that name in 1661. It is recorded in a margin of a record of 1660, which names him “Adriaen Hendricx Michielsen.” I knew the family started using the name Sinjoor around this time, but I did not know which of the dozens of men named “Adriaen Hendricx” he was. I now know he was the son of Hendrick Michielsen.

My ancestor Peter Wouter Canters signed with a mark when he witnessed a will in 1664. This taught me that he used the name Canters (I had previously only found him with a patronymic), that he could not sign his name, and that he was still alive in 1664.

My ancestor Jan Marijnissen paid 33 guilders rent to the heirs of Peeter Michielsen according to the latter’s estate inventory in 1724. I would never have found this record otherwise. These are the types of records are typically indexed by deceased, or skimmed for names of the deceased when browsing for relevant records. Rental agreements are rarely recorded in court registers.

My ancestor Adriaan van Opstal appeared in several mill tax records in Terheijden from 1756 onward. Getting all the mill tax records for the family will allow me to reconstruct who was born when, to help fill in gaps in the Terheijden church records.

What do you think?
What do you think of this new software and this website? Have you been playing around with AI tools yourself? Please leave a comment!

")
Dear Yvette,
I have been following your articles for some time now, but this one takes the cake because it opens up the way for many amateur genealogists to further study scans of archives. The development of the website is simply phenomenal and demonstrates a great deal of expertise from yourself and Willem Vermeulen.
It may take some time before other archives are linked, so I was wondering if there is a possibility to allow users to upload their own scans to VerledenTekst.nl for transcription. This would fulfill a tremendous need.
I wish you both great success!
Best regards,
Hi Han,
Great to hear you’re enthousiastic. Allowing user uploads is not a feature we are going to implement. Our web server does not have the graphic’s card or storage for that. Downloading and image processing to create the transcriptions is done on our personal computers. We already have a huge backlog of images we want to process for our own research projects and do not have the capacity to take on more. We will periodically publish the transcriptions we make on VerledenTekst so everybody can use them.
Transkribus Lite does what you describe. You can upload images, choose a model, and it will transcribe the image for you. They have the infrastructure for such an automatic transcription service. They charge a small fee, but when you create an account you get some free credits to try it out.
Hi Yvette,
thanks for the tip.
Regards,
Han Kortekaas
With help of a fellow genealogist I have been using Transkribus for a few years now, and uploaded about 200.000 scans when it was still free.
I use it in all the research I now do.
Now Transkribus is not free anymore, Loghi seems to be a perfect alternative.
Congratulations on this significant achievement! I’ve been struggling through early 17th century Leiden records this week, with little success. Maybe someone in that community has your skills and commitment, and will be inspired by your example. In the meantime, thanks for sharing the interesting information you’ve found.
Hi!
Are there any plans afoot to transcribe the Sluis Notarial records? What would it take to get such a project going?
I am not aware of any plans to transcribe the Sluis notarial records. I would be surprised if there were any since these records have not been digitized at good quality yet. Scans of the Sluis notarial records are available on FamilySearch but they do not support bulk downloads, and the scans are from microfilm and not very suitable for handwritten text recognition.
Using handwritten text recognition technology to transcribe the Sluis notarial records would take multiple steps:
1. Have the records digitized from the originals at the Zeeuws Archief. They have a free scanning-on-demand service. However, the notarial archives of Sluis cover more than 200 call numbers just for the 1600s, so I think that is beyond the scope of what is fair use of their services. The Zeeuws Archief does not provide a paid scan service for bulk scanning or quicker turn-around. We would have to contact the Zeeuws Archief to see if there are alternative options. The last time I tried this, they told me to just use the free service but spread out my requests (2 per week). With 200+ call numbers, that would take years.
2. Obtain the scans. Unfortunately, the Zeeuws Archief website does not offer bulk downloads. But we have a Reuse of Public Information law so we could make a request to receive the scans once they exist. This can take a few months.
3. Use handwritten text recognition technology to transcribe the scans.
4. Convert the transcriptions to something useful. My friend Willem is working on scripts to convert them into TXT-files and searchable PDFs (images + text).
Computer power is a limiting factor for large projects such as this. My computer can transcribe about 250 scans per hour. The notarial archives of Sluis in the 1600s would probably be easily 40,000+ scans (200+ call numbers, 200+ images per call number). I have limited capacity because I need my computer for other things too. The transcriptions take so much processing power I can only do them at night because it slows the rest down too much. If there is a demand for services like this, I could purchase a dedicated computer for transcriptions.
Thanks!!!